Introdução ao Google Cloud Functions e Arquiteturas Serverless
Antes, gostaria de contextualizar um pouco sobre essas duas coisas: Serverless e Functions.

Sobre Serverless e Functions
Afinal, o que é Serverless? Fazendo uma tradução livre, seria “arquitetura sem servidor”. Mas como isso? Segundo esse link da AWS seria você poder ter aplicações e serviços sem necessariamente ter que configurar uma infraestrutura, por exemplo. Ou seja, esse trabalho fica por conta dos Cloud Providers que configuram, gerenciam, monitoram e escalam. Cuidam da saúde da sua aplicação sem que necessariamente você tenha que montar um servidor, instalar um sistema operacional, habilitar regras de segurança, e por aí vai… Fora os trabalhos e complexidades adicionais que exigem quando você administra servidores. Functions entram como um recurso Serverless. É a possibilidade de servir através de zero ou pouquíssimas configurações uma determinada função.
Mas camarada, me conta, já estou habituado a tomar conta de servidores, na minha empresa tenho pessoas alocadas pra isso, preciso mesmo desse tal de Serverless? Não! Nada é bala de prata na tecnologia, absolutamente nada. Cada solução e ferramenta se encaixa melhor em situação X ou Y. Na minha modesta opinião, acredito em arquiteturas serverless principalmente para validações de produto e partes específicas de uma aplicação. Lembre-se que ter a infraestrutura em suas mãos ainda te dá o controle total de configurar para suas especificidades.
Um outro ponto interessante é a respeito da redução de custos que uma arquitetura desse tipo pode gerar, ao não ter um servidor alocado permanentemente mesmo em momentos de ociosidade, onde seu serviço exige menos recursos, você paga pelo total. Utilizando serviços provisionados pela nuvem, você paga apenas pelo consumo. E no caso da Google Cloud Functions, pasmem, o serviço não cobra até os dois primeiros milhões de invocações.
Motivação
Estou trabalhando em um projeto pessoal chamado “NoCinema” que consiste em um crawler que extrai e parseia os dados de sessões dos filmes por cinema e salva essas informações em um banco de dados não relacional - para posteriormente ser servido através de uma API. Já faz algum tempo que trabalho nisso, entre algumas abordagens pra tentar deixar o processo e a rotina mais automática possível, tentei utilizar módulos dentro de um conjunto de containers através do Docker Swarm na Digital Ocean, usar soluções da IBM Cloud, mas nenhuma atendeu melhor essa necessidade - além de ter custo zero - do que com os recursos da Google Cloud que possui “free tiers” interessantes.
Caso de uso “NoCinema”
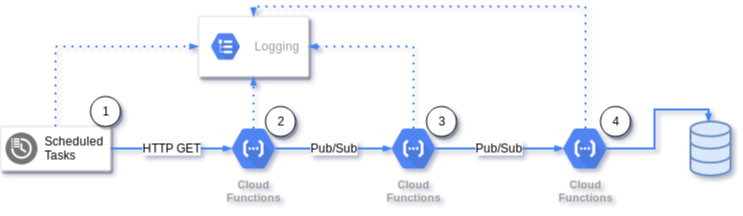
Acima, o fluxo que eu desenvolvi utilizando 100% recursos da Google Cloud. Aqui vamos limitar o escopo apenas ao Cinesystem.
👉 Escreverei mais textos abordando de forma completa essa arquitetura.
Agendei um job utilizando Cloud Scheduler, serviço semelhante ao “unix cron”. Nesse caso, após a meia noite - todo dia - ele faz um
GETpara uma rota que é servida através das Cloud Functions;Gandalf (Node.js): O primeiro serviço que possui todos os dados do cinema como cidade, local, e url (coletadas anteriormente através desse script), recebe o request, parseia as URLs uma a uma e as enfileira em um tópico Pub/Sub;
Gollum (Node.js): Por sua vez, essa etapa é responsável por receber as mensagens com as urls informadas, varrer o site e extrair as informações das sessões. Após a coleta, os dados são formatados em um JSON e enfileirados em um outro tópico que de fato armazenará as informações;
Orcs (Go): Sua única responsabilidade é receber esses dados, adicionar datas e salvá-los em um banco de dados não relacional.
Com exceção do primeiro passo, o processo todo funciona de forma assíncrona e possibilita o aumento de recursos em alguma etapa, caso essa, represente um gargalo.
Primeira Função \o/
Instale a CLI do Google Cloud SDK e no terminal execute os seguintes comandos:
$ mkdir faas-example
$ cd faas-example
$ npm init --yes
$ npm i kapti --save
$ touch index.js
Abra o arquivo index.js e adicione o código abaixo. Ele receberá uma chamada GET com uma query string url e retornará o título da página.
const kapti = require('kapti') // NPM que retorna o DOM de uma URL
exports.helloFunctions = async (req, res) => {
try {
const title = await _getPageTitle(req.query.url)
res.status(200).send({ title })
} catch (e) {
console.error(e)
res.status(500).send(e)
}
}
const _getPageTitle = async (url) => {
const $ = await kapti.getStaticPage(url)
return $('title').text()
}
Para a publicação da função, basta:
$ gcloud functions deploy helloFunctions --runtime nodejs8 --trigger-http
Caso ocorra sucesso ele retornará algumas informações, e entre elas a url onde a função está publicada e acessível. Viu como é simples?
$ curl "https://us-central1-lfernandoguedes.cloudfunctions.net/helloFunctions?url=https://fguedes.xyz"
{"title":"~fguedes 🕱 · Luís Fernando Guedes"}
Escreverei mais algumas partes relacionadas ao uso de Cloud Functions e como podemos nos beneficiar dessa tecnologia, além de abordar outros tópicos relacionados como monitoramento e escalabilidade nesse tipo de arquitetura.